
This is a short summary of a recent paper with Kyle Cranmer about a new technique that improves performance in a large class of machine learning problems. It is mainly aimed at non-experts. For the aficionados, the paper is on the arXiv and the source code with some demos is available on GitHub, conveniently binderized so you can run the code online.
A little background and motivation…
Minibatch stochastic gradient descent (SGD) is the main work horse of almost every machine learning problem out there. What minibatch SGD does in simple terms is that instead of looking at the training examples (say pictures of cats and dogs) all at once, it performs training by looking at a few of them (called a minibatch) at a time. It has been shown both empirically and analytically that this method has many advantages over training with the entire dataset all at once. In particular it improves the final performance of the network, say distinguishing power between previously unseen pictures of cats and dogs.
The reason for this, again in simple terms, is that the extra stochasticity coming from not seeing the entire dataset helps you find a better solution to your classification problem. One intuitive way of thinking about it is that if you only see a few training samples at a time, say a cute pug and a tabby, by the time you iterate over all the other samples in the dataset, you will have kind of forgotten about the tabby and the pug. So seeing the cute duo again will be more like seeing a new training sample. It’s kinda like you have more training samples when you are training your network.
Anyway, the point is that minibatch SGD is great. But… there are many problems where minibatching, that is training with only a few examples at a time, is not possible. This class of problems are generally called non-decomposable loss problems, where your optimization objective actually requires you to see the entirety of the dataset all at once (say if you are trying to teach a machine to find the cutest cat in a whole dataset), you can’t really do minibatching. So all the great things about minibatch SGD are out the window. What to do?
Introducing Backdrop
The idea of backdrop is to implement the minibatching scheme during the backward pass of the network instead of the forward pass. What this means in practice is that when during the computation of the objective, the entire dataset is used but when it comes to modifying the parameters of the network, only a small number of the samples will be used. To keep with the problem of finding the cutest cat, in this method, we would look look at all the cat pictures at once, but when it comes to learning from it, we only look at a small number of the pictures.
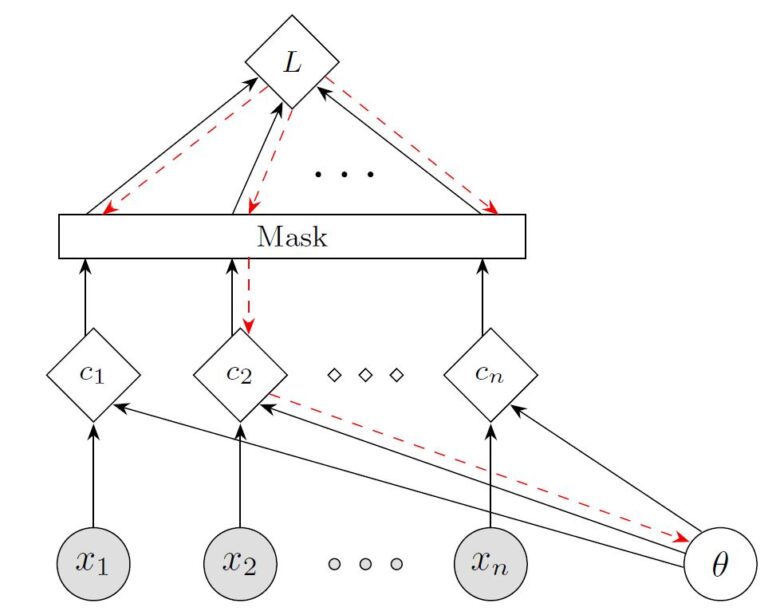
Here is a cartoon of backdrop implemented on problems with non-decomposable loss. Here the samples, parameters and the loss objective are denoted as x, θ and L. The solid white liens denote the forward pass of the network and the dashed cyan lines denote the gradient computation in the backward pass. The goal of the backdrop masking layer is to propagate the backward gradients for only a fraction of the samples (in this case only for sample number 2.) In this way we recover many of the advantages of minibatch stochastic gradient descent when it comes to generalization performance.
Applications in the sciences
There is an entirely different class of problems that can greatly take advantage of backdrop which come up often in various scientific fields. These problems are defined by the nature of their datasets which comprise of a a small number of samples but each sample is huge.
backgAs an illustraitve example, consider the the Millenium Run, a large-scale computer simulation used to investigate how the distribution of matter in the Universe has evolved over time, in particular, how the observed population of galaxies was formed. Significantly, it took millions of CPU hours to accurately follow the evolution of the 10 billion particles involved in the simulation. Now, if we want to use the outcome of this simulation as input for a machine learning project, we would have a single data point to learn from.
Interestingly, the universe at these large scales has a hierarchical structure: at the largest scales it is made up of vast filaments, as we zoom in, we start to see dark matter halos at (mostly at the intersection of the filaments) and inside each halo exist many galaxies (see image). In other words, there are many realizations of the features of the problem (from large to small: filaments, halos and galaxies) at each scale of the image. In a sense, the single sample of this cosmology simulation problem is comprised of many many subsamples, each of which carries an immense amount of information. The same kind of hierarchical structure exists in many other fields from quantum lattice simulations, medical or satellite imaging and graph analysis.
So the question is now how to take advantage of this multi-scale hierarchical sub-sample structure of the data. One approach would be to cut the data into a bunch of different pieces and use these individual pieces for training. But it’s not clear this can be done without destroying the structure of the data.
The way backdrop solves this problem is by computing the gradient steps with respect to only a fraction of the features at each scale. Intuitively, this is a method of implementing minibatching on the gradients without having to figure out how to cut up the data. In practice, this is done by inserting masking layers after convolutional layers associated with detecting features at scales of interest.
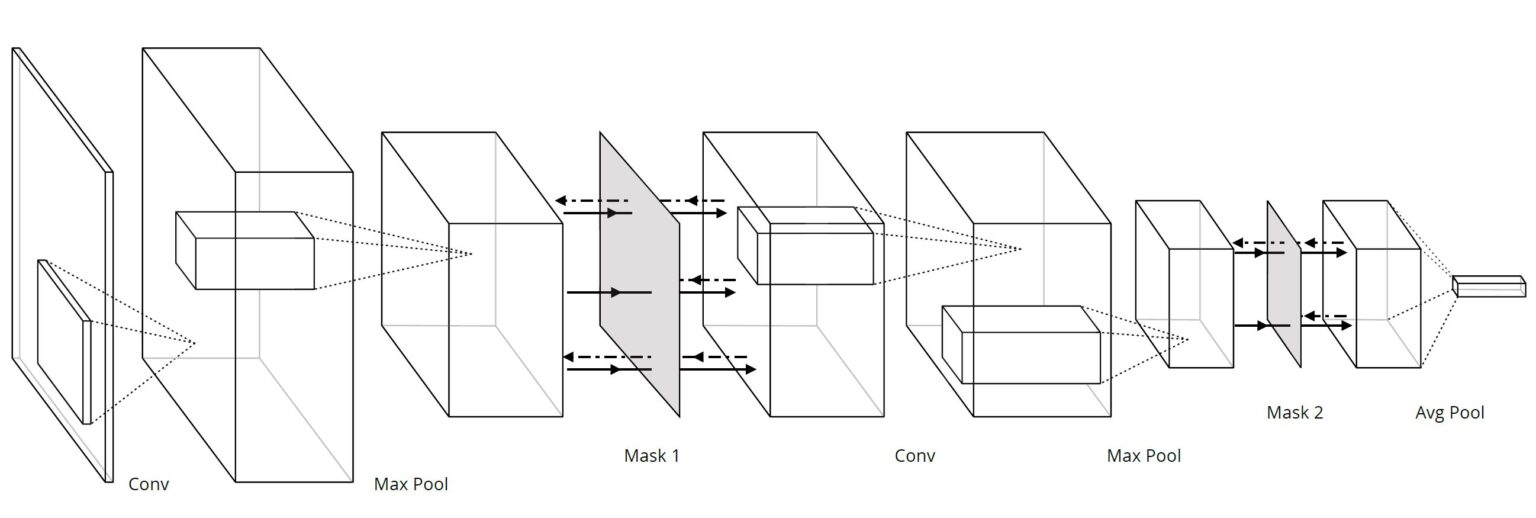
For more details about how backdrop is implemented and how much performance improvement one can expect in different types of problems, look up the paper on the arXiv.
The title image of this post is motivated by the title of the paper which was in turn inspired in part by the wrestling move Backdrop Suplex.